Merchants using POS (Point of sales) payment platform frequently switch to other POS Platform payment providers because of the wide range of POS payment platform available in India and various incentives these POS platforms give to merchants. It is believed that typical churn rates lie between 20 to 30% in a year. For POS Platforms, churn means high costs in the form of lost profits, but also the entire customer lifetime value (LTV) to their revenues, and other value contribution such as word of mouth marketing.
Yet, it is still a rarity that POS Platforms make any efforts to get back those churned merchants back into their folds, although experience shows that the probability of winning back them is encouragingly high. It is comparatively cheaper (just a third) to win back a churned merchant than to win a new one, because former customers already understand the platform and also POS companies know a lot about their customers such as how these merchants use their POS Platform, the complaints churned these merchants have made, and their preferences etc. This makes them easier to address the issues of the existing merchants who are about to churn.
How churn analysis and LTV is done:
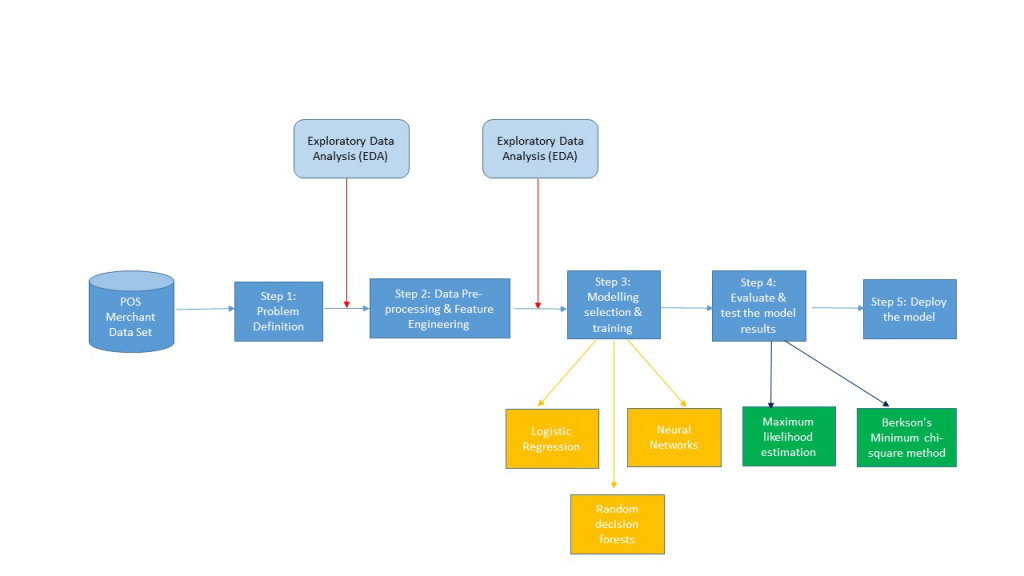
The churn analysis can be performed for a POS payment platform using their existing merchant datasets to forecast the probability of churn for merchants who are still actively using the POS platform. The objective of the project is to predict the churn before it happens and prevent the merchants from churning.
Churn analysis in data science is a classification problem. In the first step, often forecasting techniques such a random decision forests, regression procedures, or neural networks are used to classify typical churners (class 1) and typical non-churners (class 0) based on the customer data set. In the second step, the same model can be further used on non-classified customers, where churn probability will be calculated based on the differentiation pattern learnt in the first step.
Once churn analysis is done, the next step is to identify a specific set of attributes in the dataset that are strong indicators of a more favorable Lifetime Value (LTV) of a particular merchant.
Our approach to Churn analysis and LTV for a large Indian POS Payment platform:
We investigated the merchant dataset provided by an Indian POS Platform as part of churn analysis project. Some 14000 merchants with around 40 attributes each and 4 million transactions are analyzed. We extensively used random decision forests and regression procedures to analyze churn and determine the LTV of the merchants.
Problem definition:
Activity Churn: Activity Churn is defined as no transactions for a particular merchant for a period of 30 days or more. Find the set of attributes in the data that are strong indicators of Activity Churn for a particular merchant. Deliverable will be a report on the set of attributes and proof points in the form of a report validating the conclusion.
Lifetime Value (LTV): Identify the specific set of attributes in the data that are strong indicators of a more favorable Lifetime Value (LTV) for a particular merchant. Deliverable will be a report on the set of attributes and proof points in the form of a report validating the conclusion.
Feature Engineering:
The initial set of raw attributes from the transaction data are processed to build an informative, discriminating and independent feature set. The data contains both numeric and categorical information (merchant type/merchant category etc.). Based on the modeling technique, categorical values are baselined to avoid collinearity. In such cases, the categorical values are dummified while building data feature vectors.
Feature Extraction:
For each merchant, the raw transactional data are aggregated using various statistical methods and time series analysis. We extracted around 50 features from attributes such as total amount, transaction status, merchant timelines, hibernation periods, etc. The primary reasons for doing this are as follows: 1) Raw merchant transactional data cannot be used as is. 2) Simplification of models to make them easier to interpret. 3) Shorter training times leading to more experiments. 4) Enhance generalization by reducing overfitting.
Model Selection & Training:
The dependent or the outcome variable of interest, Churn/No Churn was constructed as a ‘yes/no’ dichotomous indicator based on the 30-day hibernation and length of the merchant membership. Merchants who are members for more than 90 days are considered in our analysis.
The Distribution: We consider first the case where the response is binary, assuming only two values that for convenience we code as 1 or 0. In our case, we define the response as yi= 1 if the merchant has churned, 0 otherwise.
We view yi as a realization of a random variable Yi that can take the values 1 and 0 with probabilities πi and 1 − πi , respectively. The distribution of Yi fits Binomial distribution with parameter πi.
Logistic Regression: In our sample merchant transactional data set, we have 9k independent observations y1,.,yk, and that the i-th observation can be treated as a realization of a random variable Yi . We assume that Yi has a binomial distribution
Yi ∼ B(ni , πi)
with binomial denominator ni and probability πi. With individual data ni = 1 for all i. This defines the stochastic structure of our model for analysis with underlying probability πi as a linear function of the predictors
logit(πi) = xiβ
where xi is a vector of covariates derived from the feature vector discussed above and β is a vector of regression coefficients.
Model fit: Since our response variable takes two values, we have used various model estimation algorithms like Berkson’s minimum chi-square method, Maximum likelihood estimation(MLE), Gibbs Sampling. We found that MLE performed the best.
The accuracy of 82% was witnessed during the testing phase, which is the same as we experienced when training and predicting on the data.
Data processing framework – The BigAI
Processing datasets that consist of data related to 14000 merchants with around 40 attributes each and 4 million transactions needed a different data processing framework. BigAI is built on open source technologies such as Hadoop, Spark, Kafka, and more, and can process data both in real-time and on batch. BigAI is continuously tuned and improved to increase the efficiency of the framework. The following is the diagram of the BigAI framework.
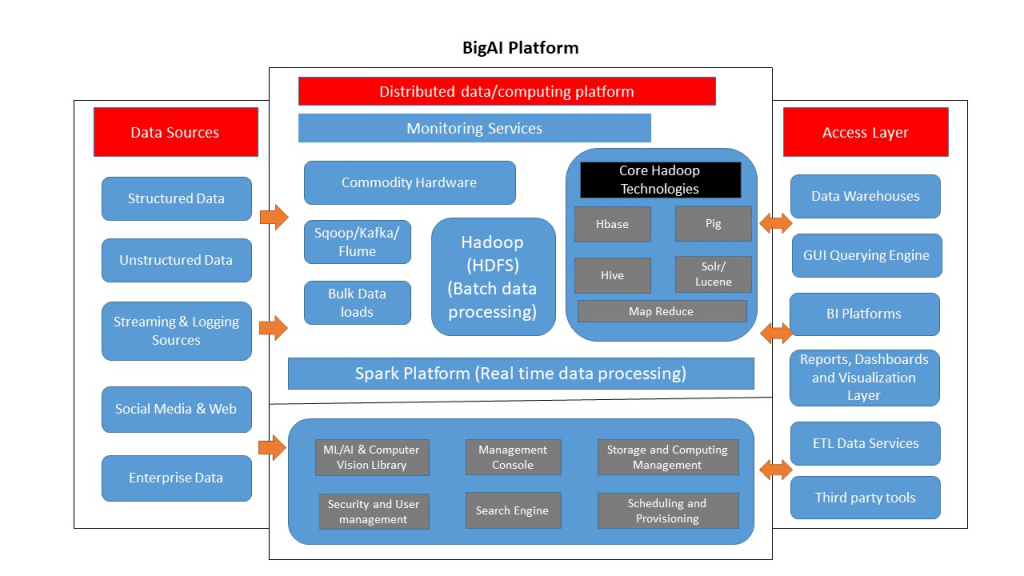
BigAI supports the collection, processing, storing, and retrieval of large volumes of datasets. It can process different types of data including structured, unstructured, streaming, log data, images, enterprise legacy data, and many more. It has 900 different data connectors for different data sources. BigAI can also scale horizontally to billions of data points. BigAI architecture defines a schema-less storage, so that it is flexible enough to cater to any needs without constant schema changes.
Conclusions:
- Churn Analysis
- So we can conclude here, that we have rather precise knowledge about the regression coefficients (because the confidence intervals are rather small) and that there is no doubt, that total error amounts, total error, 30-day hibernations are positively contributing towards churn.
- LTV Analysis
- So we can conclude here, that we have rather precise knowledge about the regression coefficients (because the confidence intervals are rather small) and that there is no doubt about, higher total successful transactions, total amounts, total average amounts, 7/15 day hibernations are positively contributing towards LTV.
- Higher moving average of transactions and the total amount contributed positively towards LTV
- Even a better accuracy (~95%) can be achieved with merchant info (size, activity, social perception, etc..), demographics, etc.
Other benefits:
After the churn analysis was done on the dataset, merchants who are likely to churn risk over various times (the next 30 days, 60 days, etc..) were identified. These merchants were contacted individually and a marketing campaign was run, resulting in significantly more merchants persuaded not to churn.